

数林团队的技术工程师们演示时,经常会有代理商或是客户抛出类似这样问题:
1.某针对金蝶或用友的BI产品和数林BI感觉效果差不多啊,数林BI产品有何特点?
2.数林BI能为我们金蝶或是用友BI客户带来哪些与众不同的价值?我们为什么要选择数林BI产品?
3.贵公司的产品和市面上其他标准化BI产品最大的区别在哪呢?
......
诸多问题,原因归结起来无非是对于我们数林BI产品的独到之处不熟悉、不了解。那么今天我们将通过一些案例和大家盘点下数林BI与其他BI产品相比的特别之处。
一、框架
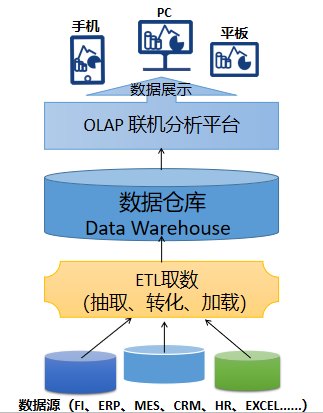
众所周知,对于BI产品而言,是面向多数据源的,例如财务系统、Erp系统、HR系统、CRM系统、MES、Excel等等。要分析这些数据,首先需要对数据进行抽取、转化、加载等。传统BI产品在此基础上必须按用户的需求针对性的撰写T-SQL代码等取数逻辑,ETL到数据仓库,然后再把数据展示到OLAP联机分析平台,用户可通过PC端、移动端(平板、手机)等等查看需求的报表,如下图所示:
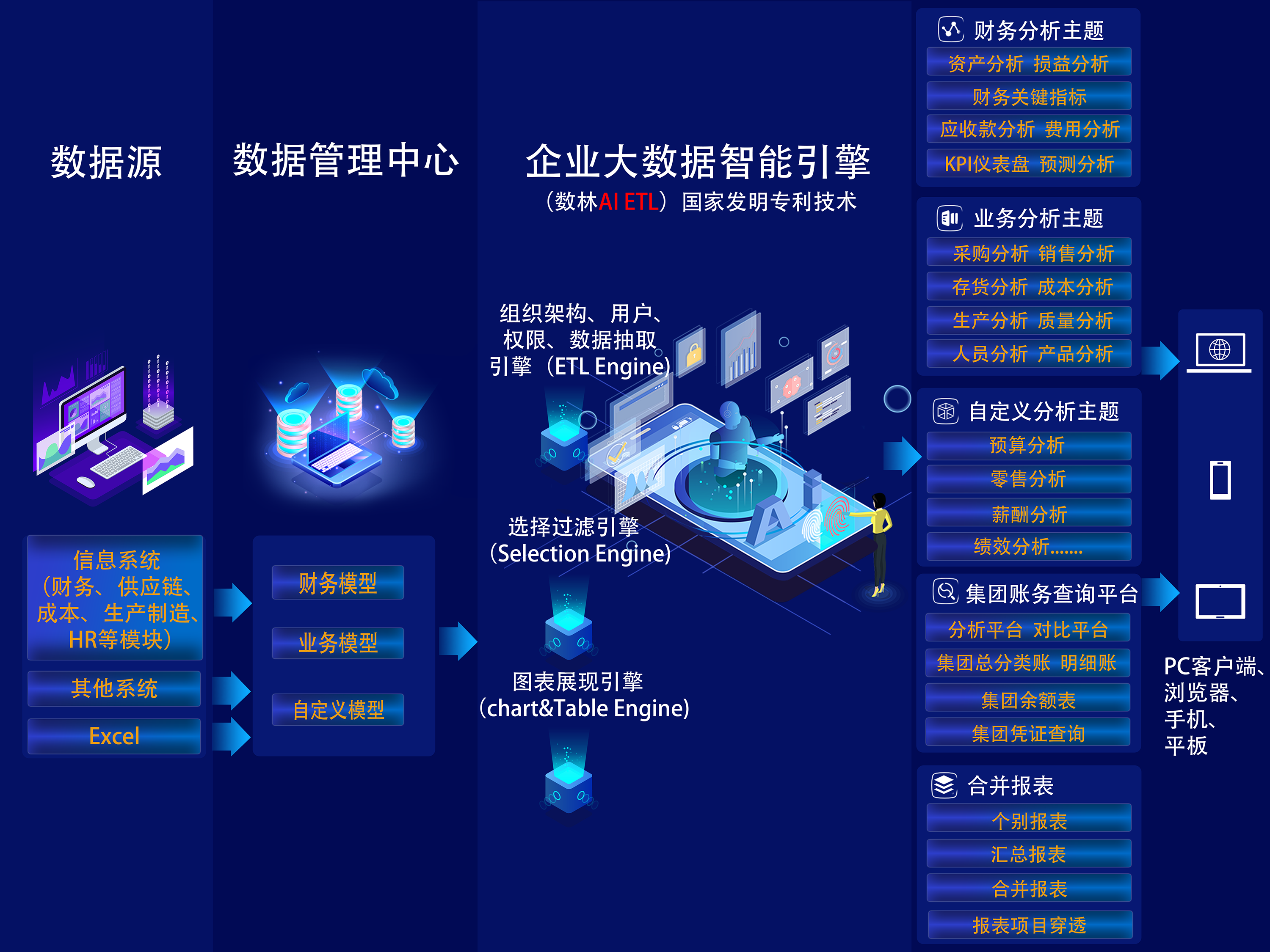
数林BI与传统BI相比之下,如下图。在数据处理上设置了基于三大模型(财务、业务、自定义模型)的数据模型管理中心。用户无需编写取数代码,只需在界面选择配置取数方案,数林BI系统将根据用户指定的方案和ERP产品、用户的实际账套情况自动生成ETL逻辑。我们称之为“AI ETL”。
二、ETL部分
案例1:A企业有十几个财务账套,需要取会计科目、核算项目的数据进行收入、成本、费用分析,上线传统的BI产品后,一旦面临会计科目、核算项目变更,或者增加一个财务账套等问题。往往需要花费许多时间找经销商沟通,找原技术人员反复确认后,再修改取数代码,确认修改后的数据准确性,过程稍有不慎,往往数据不准确而不自知。而过了若干年后,万一原来的技术人员离职,企业却需要对科目体系进行调整时(诸如:适应新的会计准则、细化账务的颗粒度提升分析价值),由于新的技术人员不理解原技术人员的代码,也不一定理解财务知识,A企业还需花时间与技术人员解释相关财务概念,最后取数逻辑虽然可以正确执行,但却始终无法确保数值的准确,导致项目不得不搁置、终止......
案例2:B企业有两个财务账套,需对应收账款进行分析,一个应收账款中挂有“客户”这一核算项目,另一账套中不挂,其他BI产品供应商,分别针对挂和没挂核算项目的两个账套分别编写了取数代码,并把数据整合在一起,某天,B企业另一账套将应收账款也禁用修改为带“客户”的核算项目,那么该账套的应收账款取数将会失效,更别提自动取到新的带有“客户”的应收账款数据,该企业又要花费时间、精力、财力找技术人员沟通变动、修改代码、确认数据有效。
案例3:C企业,上线了某标准化BI产品,应收账款分析时,只能按照科目代码或者科目名称二者中的某一项写死代码,如果公司业务发展了,想新设二级科目,把国内和国外的应收账款分开管理统计,则就需要对取数代码进行修改,而增加二级科目这么简单的变化,但因为不是简单的改个过滤条件,一般的技术人员还不能胜任。更别提如果是集团账套,每个账套可能都随时面临会计科目和核算项目的新增、修改、级次变动等等。
假设难以确保BI产品数据的准确性,那么不值得用户信任的BI报表即便再美轮美奂也毫无价值可言。由上述案例可见,一个BI项目的实施成本、实施风险等在数据处理上(ETL)占了绝大部分,所以说,数据取数(ETL)是BI项目的心脏。
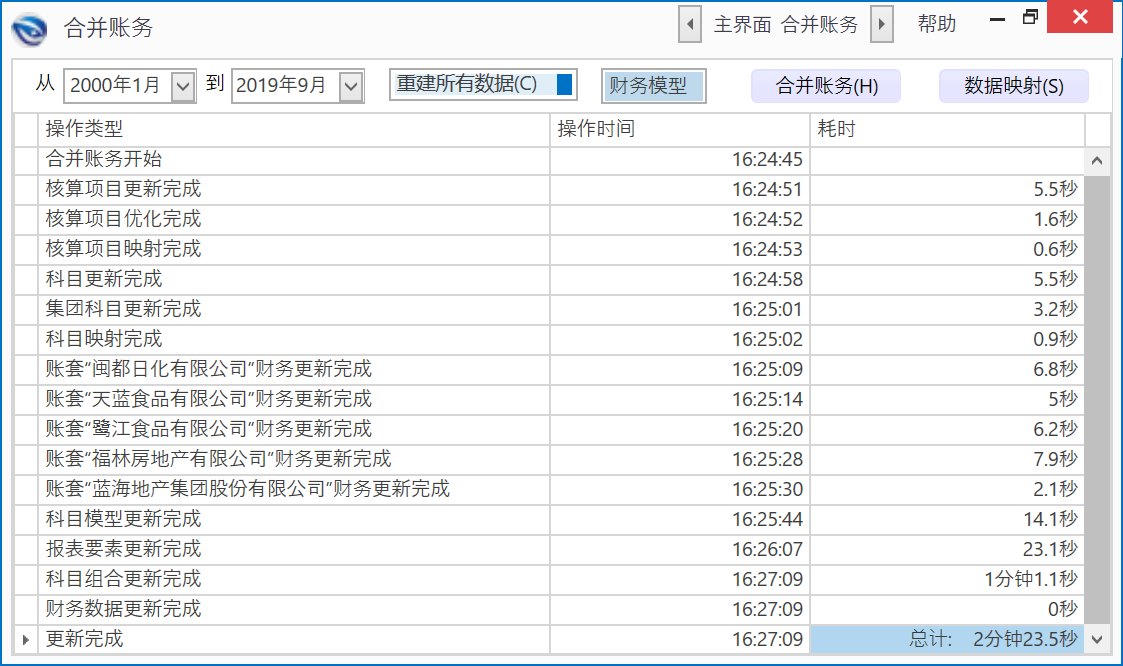
针对案例1中A企业的情况,数林BI系统可将企业中不同账套的的数据合并成集团一套账,如下图。若是后续增加了新的财务账套,在初始设置后可重新合并成集团一套账,若是科目代码、科目名称等没有变更,用户只需在软件界面中选择【填补新增数据】即可。
针对案例2中B企业的情况,若是企业后续修改了核算项目,在数林软件中,用户只需在界面上修改配置,如下图所示:
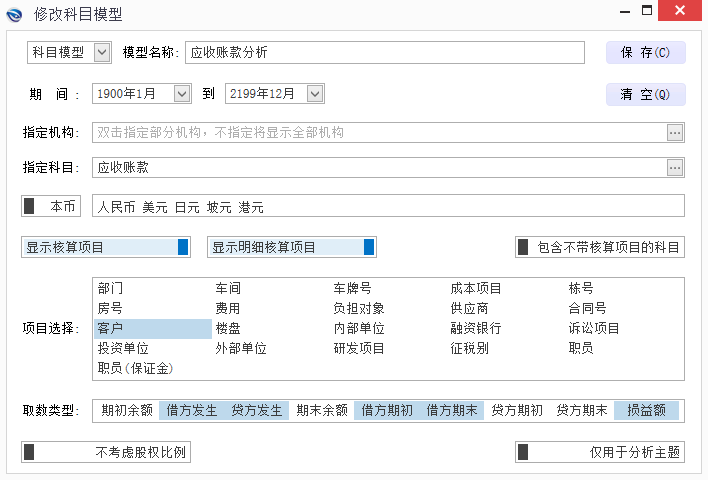
核算项目有几级,我们的“AI ETL”,在系统中智能数据引擎自动判断,用户无需写代码,假设厂商或经销商相关技术人员不能继续对该项目给予技术支持,也无需四处寻找专业技术人员修改。
对于会计科目不一致时,数林BI产品只需在界面上进行科目映射即可,两家公司的会计科目会依据用户的设置自动匹配。
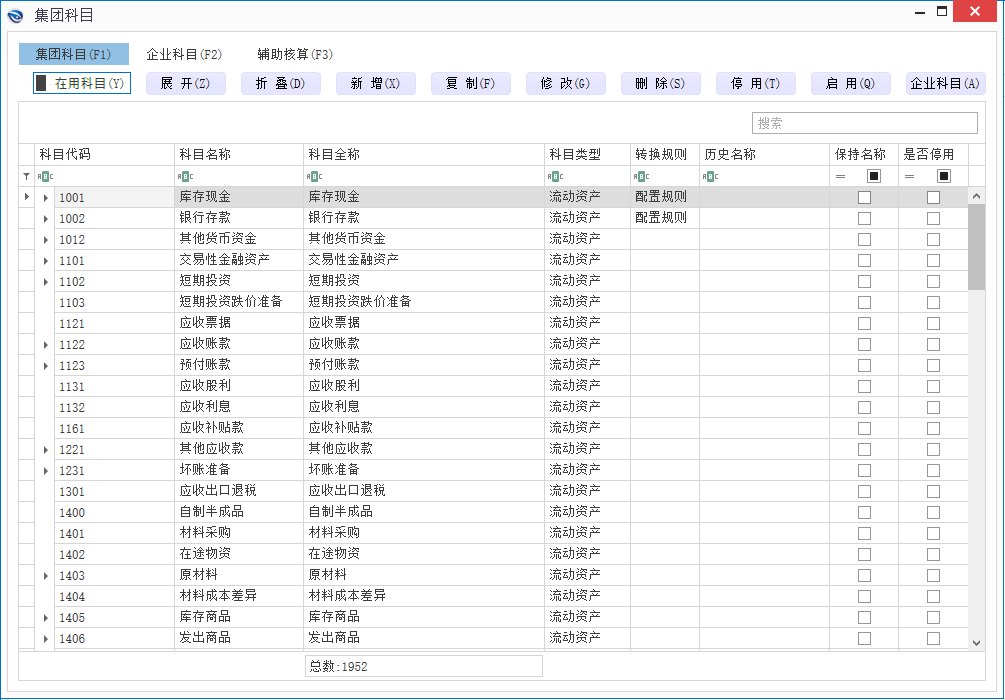
针对案例3中C企业的情况,假设应收账款下,新增了核算项目或是科目级次增加,数林BI系统可自动识别科目级次和核算项目,用户只需在界面中选择所需要的会计科目和核算项目保存,只要一级科目代码不变或映射不变,不管用户是否增加核算项目,产品升级等,数林ETL引擎都会智能根据财务系统的当前情况自动生成准确的ETL代码。如下图:
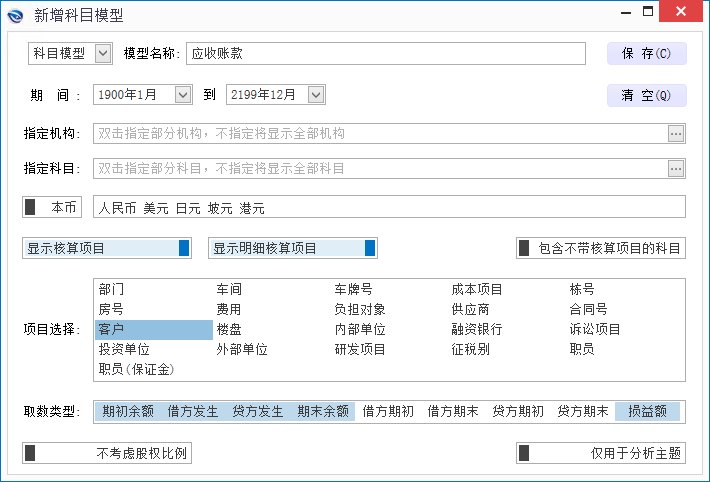
简而言之,一个BI项目的实施成本、维护成本、实施风险基本上是由数据处理(ETL)决定的,一旦BI展示的数据不是用户关注的,甚至是错误的,BI可能不仅没有价值,甚至可能引导管理者错误的决策,后果不堪设想。而在数据取数上,数林BI系统极大的减少了项目所存在的实施成本、实施风险等,用户更无需担心数据是否准确。
三、数据更新部分
案例:某集团公司上线了一套标准化BI产品,由于数据量大的原因不可能每次花几个小时的时间完整更新,因此选择了数据增量更新,更新上个月1号到现在的数据,容错期只有一个月。假设该集团公司在十二月通过反结账到一个月外的时间段,修改了九月或十月的数据,那么如何正确更新一个月前的数据将是一个难题,要么找技术员修改更新的取数条件,要么只能修改服务器系统的时间到九月,触发九月份数据的更新,而此时系统中有员工登入系统录入了数据,那么这条数据便成了九月或是十月的数据,这对于该公司而言,风险太大,数据准确性也无法保证......
针对上述情况,数林BI中设置了两种自定义更新模式,一种是系统后台自定义更新时间,一种是人工手动更新(以业务模型为例),无论何种模式,用户皆可以选择数据更新的范围。如下图所示,确保数据的准确高效更新。
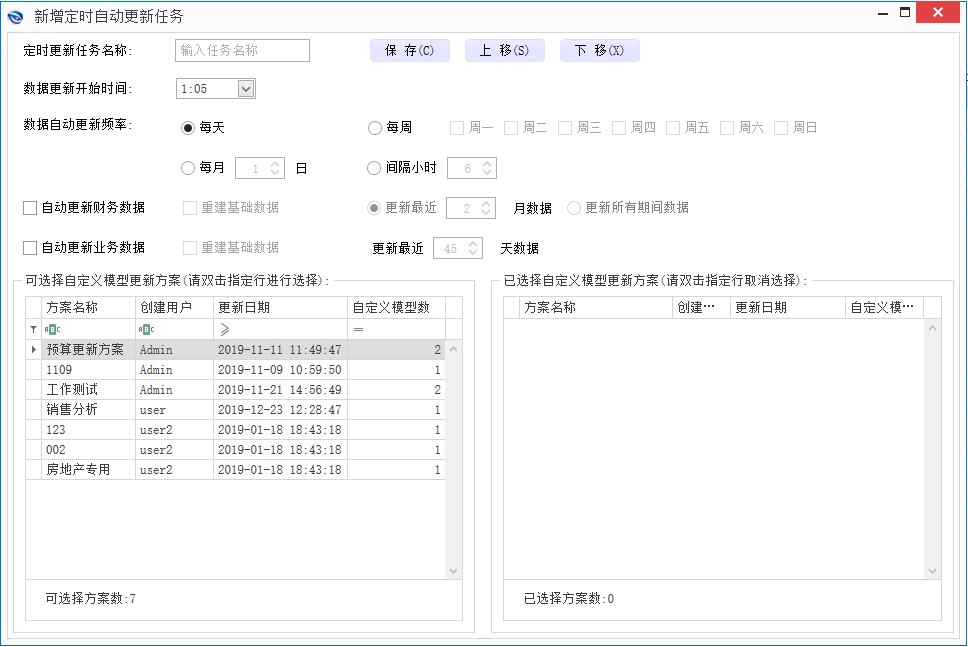
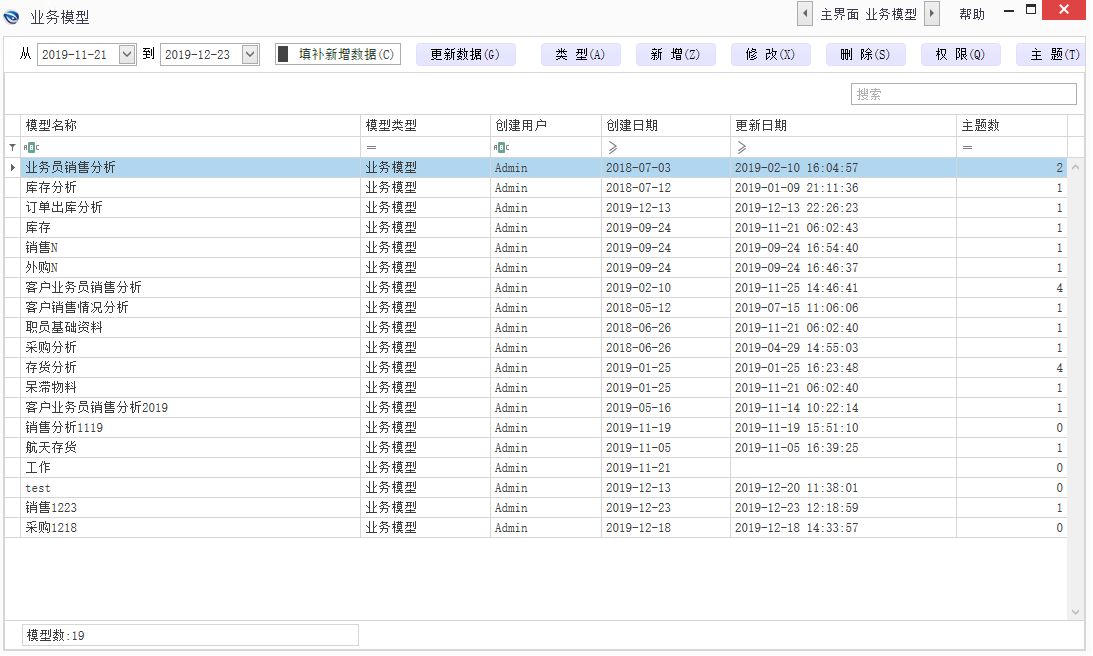
这里再补充说明下,我们系统中的自定义模块对Excel表格还可以进行增量更新,以减少Excel的数据量,增加效率、防止误改,这是市面上其他BI产品通常所不具备的功能,如下图:
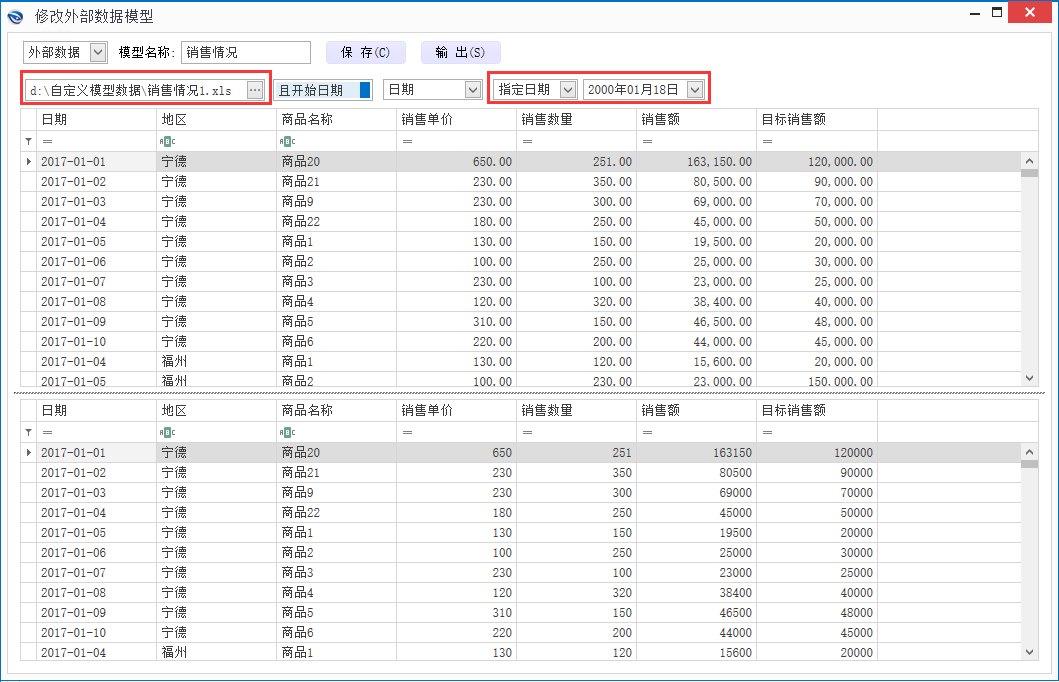
四、数据源管理部分
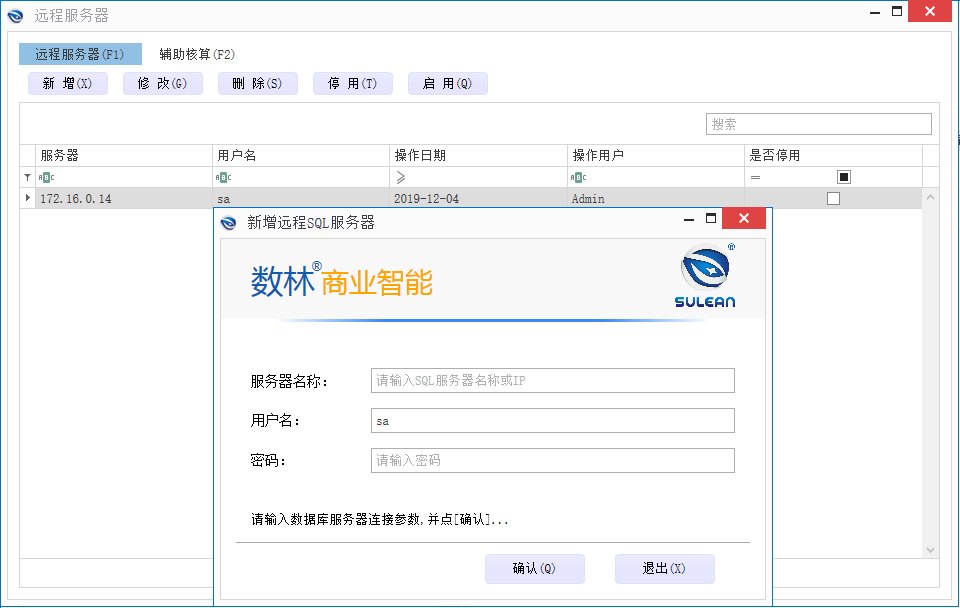
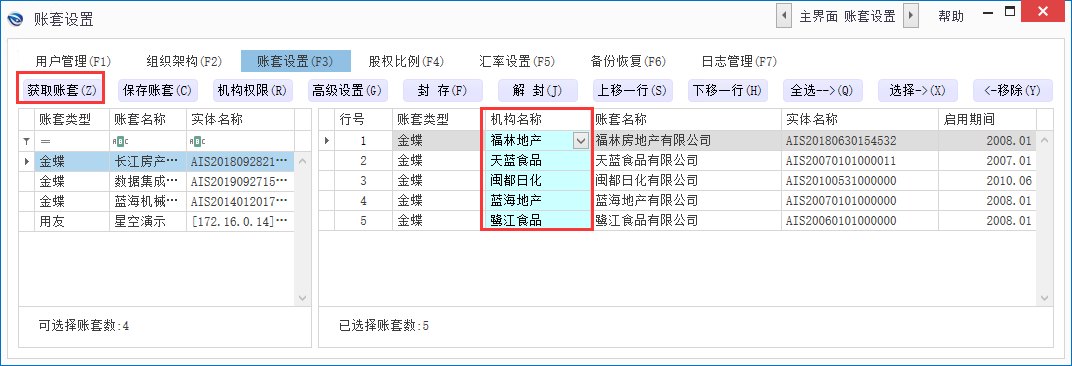
假设用户要修改服务器Ip地址、密码、实体名等,传统BI产品往往需要按照数据模型逐个配置,而在我们数林BI系统中只需要通过账套设置统一进行修改配置即可。如下图所示:
五、总结
上述稍微举了几个例子,数林BI与其他标准化BI产品的核心区别在于“心脏”(ETL)不同,基于受国家专利(专利号:ZL201710227461.6)保护的、由AI驱动的ETL,无论从实施周期、实施成本、实施风险还是维护成本、项目效果及性价比,尤其是数据准确性上,数林BI都具有无可比拟的优势。
我们用一个表格来归纳总结数林BI与其他BI的主要区别:
优势区别点 | 传统BI产品 | 数林BI |
核心框架 | 传统框架,所有的操作都靠固化的T-SQl代码或其他ETL代码取数,一旦ERP产品升级或者客户的应用稍有调整,将面临BI数据要么取不到,要么出错的情况。 | 已获国家发明专利授权的专利框架(专利号:ZL201710227461.6),用户只需在界面选择配置,系统根据用户配置和ERP产品、账套情况智能生成ETL逻辑(AI ETL) 。如果账套的环境发生改变,比如ERP产品升级,客户的应用稍有调整,数林BI将智能生成新的ETL逻辑,自动适应。 |
数据处理(ETL) | 标准产品只针对单一的ERP账套,多个公司的账套合并取数需要逐个账套编写代码支持,任意一个账套稍有调整都不得不修改ETL取数逻辑。 | 原生支持合并多个ERP账套的财务和业务数据源。无需任何代码,即可将分散的ERP数据合并成集团数据中心。 |
科目、核算项目、基础资料、代码级次、单据自定义字段等任何改变都需要改代码。 | AI驱动,数据智能化ETL,客户无需担心如何取数。需要调整的,用户直接在界面配置保存,除此之外的,ETL可智能适应。 | |
科目体系和核算项目的调整梳理,全部通过写死的取数代码实现,成本居高不下且不论,一有调整更是伤筋动骨。 | 科目体系和核算项目的调整梳理,可通过映射轻松实现。并且用户还可根据自身需要随时停用或者再启用映射体系。 | |
财务报表级的分析要么不能做,要么只能通过Excel导入僵化的孤立的报表进行分析。 | 原生支持财务报表,一键或定时ETL取数。支持各种分析,甚至穿透到科目、核算项目数据。 | |
所有的数据模型改动离不开,反复沟通,写代码,核对确认甚至经常面临改了A,却不小心导致B出错的关联错误 | 用户动动鼠标即可保证数据正确同步。 | |
维护阶段离开了原来的ETL代码编写人员,成本大增,甚至项目停摆 | 维护阶段,普通用户即可按需调整取数逻辑,确保数据的准确性,项目的延续。 | |
更新 | 服务器调度更新 | 服务器调度更新+客户端自主更新 |
以完全更新为主,部分产品支持预设增量更新,不支持用户手工指定数据更新范围 | 完全更新+调度增量更新+人工选择范围手动更新 | |
如果模型间数据有依赖关系,只能预估执行时间,人工设置更新间隔。一旦发生阻塞,数据错误在所难免 | 数据更新时,可以按照依赖关系指定模型的先后更新顺序。 | |
数据管理 | 修改服务器IP地址、密码、实体名等配置繁琐重复 | 账套管理统一直接修改,对所有来源于该账套的模型有效。 |
